When investigating a grant, Open Philanthropy staff often make probabilistic predictions about grant-related outcomes they care about, e.g. “I’m 70% confident the grantee will achieve milestone #1 within 1 year.” This allows us to learn from the success and failure of our past predictions and get better over time at predicting what will happen if we make one grant vs. another, pursue one strategy vs. another, etc. We hope that this practice will help us make better decisions and thereby enable us to help others as much as possible with our limited time and funding.[1]
Thanks to the work of many people, we now have some data on our forecasting accuracy as an organization. In this blog post, I will:
- Explain how our internal forecasting works. [more]
- Present some key statistics about the volume and accuracy of our predictions. [more]
- Discuss several caveats and sources of bias in our forecasting data: predictions are typically scored by the same person that made them, our set of scored forecasts is not a random or necessarily representative sample of all our forecasts, and all hypotheses discussed here are exploratory. [more]
1. How we make and check our forecasts
Grant investigators at Open Philanthropy recommend grants via an internal write-up. This write-up typically includes the case for the grant, reservations and uncertainties about it, and logistical details, among other things. One of the (optional) sections in that write-up is reserved for making predictions.
The prompt looks like this (we’ve included sample answers):
Do you have any new predictions you’re willing to make for this grant? […] A quick tip is to scan your write-up for expectations or worries you could make predictions about. […]
| Predictions | Scoring (you can leave this blank until you’re able to score) | |||
| With X% confidence… | …I predict that (yes/no or confidence interval prediction)… | …by time Y (ideally a date, not e.g. “in one year”) | Score (please stick to True / False / Not Assessed) | Comments or caveats about your score |
| 30% | The grantee will produce outcome Z | End of 2021 | ||
After a grant recommendation is submitted and approved, the predictions in that table are logged into our Salesforce database for future scoring (as true or false). If the grant is renewed, scoring typically happens during the renewal investigation phase, since that’s when the grant investigator will be collecting information about how the original grant went. If the grant is not renewed, grant investigators are asked to score their predictions after they come due.[2] Scores are then logged into our database, and that information is used to produce calibration dashboards for individual grant investigators and teams of investigators working in the same focus area.
A user’s calibration dashboard (in Salesforce) looks like this:
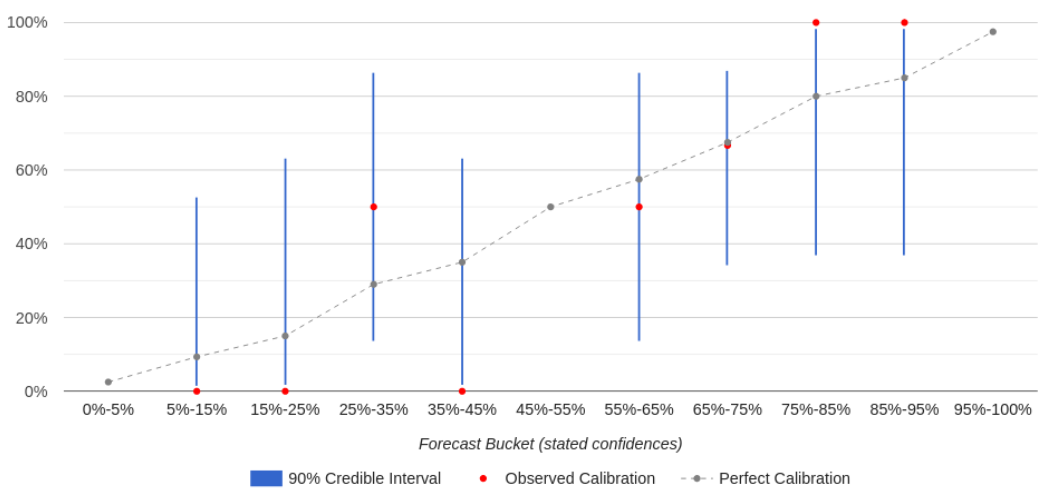
The calibration curve tells the user where they are well-calibrated vs. overconfident vs. underconfident. If a forecaster is well-calibrated for a given forecast “bucket” (e.g. forecasts they made with 65%-75% confidence), then the percent of forecasts that resolved as “true” should match that bucket’s confidence level (e.g. they should have come true 65%-75% of the time). On the chart, their observed calibration (the red dot) should be close to perfect calibration (the gray dot) for that bucket.[3] If it’s not, then the forecaster may be overconfident or underconfident for that bucket — for example, if things they predict with 65%-75% confidence happen only 40% of the time (overconfidence). (A bucket can also be empty if the user hasn’t made any forecasts within that confidence range.)
Each bucket also shows a 90% credible interval (the blue line) that indicates how strong the evidence is that the forecaster’s calibration in that bucket matches their observed calibration, based on how many predictions they’ve made in that bucket. As a rule of thumb, if the credible interval overlaps with the line of perfect calibration, that means there’s no strong evidence that they are miscalibrated in that bucket. As a user makes more predictions, the blue lines shrink, giving that user a clearer picture of their calibration.
In the future, we hope to add more features to these dashboards, such as more powerful filters and additional metrics of accuracy (e.g. Brier scores).
2. Results
2.1 Key takeaways
- We’ve made 2850 predictions so far. 743 of these have come due and been scored as true or false. [more]
- Overall, we are reasonably well-calibrated, except for being overconfident about the predictions we make with 90%+ confidence. [more]
- The organization-wide Brier score (measuring both calibration and resolution) is .217, which is somewhat better than chance (.250). This requires careful interpretation, but in short we think that our reasonably good Brier score is mostly driven by good calibration, while resolution has more room for improvement (but this may not be worth the effort). [more]
- About half (49%) of our predictions have a time horizon of ≤2 years, and only 13% of predictions have a time horizon of ≥4 years. There’s no clear relationship between accuracy and time horizon, suggesting that shorter-range forecasts aren’t inherently easier, at least among the short- and long-term forecasts we’re choosing to make. [more]
2.2 How many predictions have we made?
As of March 16, 2022, we’ve made 2850 predictions. Of the 1345 that are ready to be scored, we’ve thus far assessed 743 of them as true or false. (Many “overdue” predictions will be scored when the relevant grant comes up for renewal.) Further details are in a footnote.[4]
What kinds of predictions do we make? Here are some examples:
- “[20% chance that] at least one human challenge trial study is conducted on a COVID-19 vaccine candidate [by Jul 1, 2022]”
- “[The grantee] will play a lead role… in securing >20 new global cage-free commitments by the end of 2019, improving the welfare of >20M hens if implemented”
- “[70% chance that] by Jan 1, 2018, [the grantee] will have staff working in at least two European countries apart from [the UK]”
- “60% chance [the grantee] will hire analysts and other support staff within 3 months of receiving this grant and 2-3 senior associates and a comms person within 6-9 months of receiving this grant”
- “70% chance that the project identifies ~100 geographically diverse advocates and groups for re-grants”
- “[80% chance that] we will want to renew [this grant]”
- “75% chance that [an expert we trust] will think [the grantee’s] work is ‘very good’ after 2 years”
Some focus areas[5] are responsible for most predictions, but this is mainly driven by the number of grant write-ups produced for each focus area. The number of predictions per grant write-up ranges from 3 to 8 and is similar across focus areas. Larger grants tend to have more predictions attached to them. We averaged about 1 prediction per $1 million moved, with significant differences across grants and focus areas.
2.3 Calibration
Good predictors should be calibrated. If a predictor is well-calibrated, that means that things they expect to happen with 20% confidence do in fact happen roughly 20% of the time, things they expect with 80% confidence happen roughly 80% of the time, and so on.[6] Our organization-wide calibration curve looks like this:
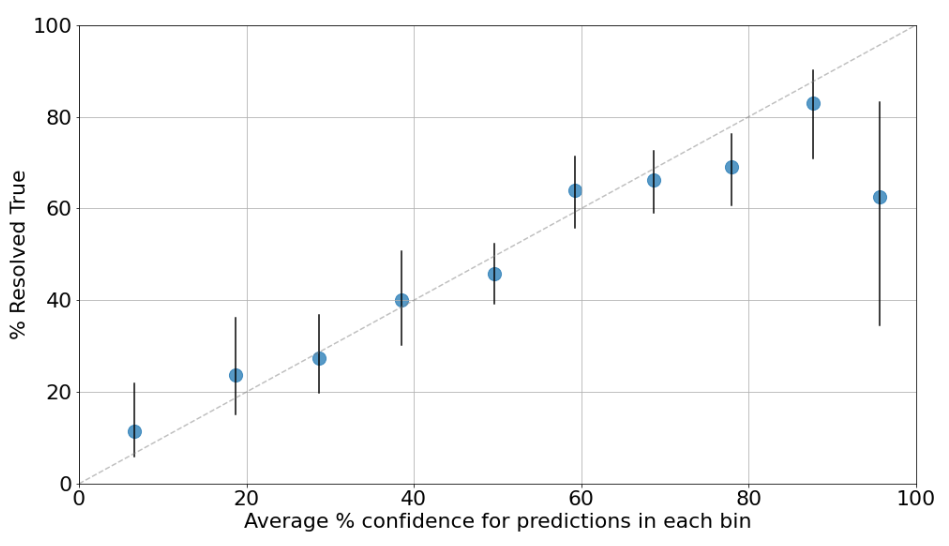
To produce this plot, prediction confidences were binned in 10% increments. For example, the leftmost dot summarizes all predictions made with 0%-10% confidence. It appears at the 6% confidence mark because that’s the average confidence of predictions in the 0%-10% range, and it shows that 12% of those predictions came true. The dashed gray line represents perfect calibration.
The vertical black lines are 90% credible intervals around the point estimates for each bin. If the bar is wider, that generally means we’re less sure about our calibration for that confidence range because we have fewer data points in that confidence range.[7] All the bins have at least 40 resolved predictions except the last one, which only has 8 – hence the wider interval. A table with the number of true / false predictions in each bin can be found in a footnote.[8]
The plot shows that Open Philanthropy is reasonably well-calibrated as a whole, except for predictions we made with 90%+ confidence (those events only happened slightly more than half the time) and possibly also in the 70%-80% range (those events happened slightly less than 70% of the time). In light of this, the “typical” Open Phil predictor should be less bold and push predictions that feel “almost certain” towards a lower number.[9]
2.4 Brier scores and resolution
On top of being well calibrated, good predictors should give high probability to events that end up happening and low probability to events that don’t. This isn’t captured by calibration. For example, imagine a simplified world in which individual stocks go up and down in price but the overall value of the stock market stays the same, and there aren’t any trading fees. In this world, one way to be well-calibrated is to make predictions about whether randomly chosen stocks will go up or down over the next month, and for each prediction just say “I’m 50% confident it’ll go up.” Since a randomly chosen stock will indeed go up over the next month about 50% of the time (and down the other 50% of the time), you’ll achieve perfect calibration! This good calibration will spare you from the pain of losing money, but it won’t help you make any money either. However, you will make lots of money if you can predict with 60% (calibrated) confidence which stocks will go up vs. down, and you’ll make even more money if you can predict with 80% calibrated confidence which stocks will go up vs. down. If you could do that, then your stock predictions would be not just well-calibrated but also have good “resolution.”
A metric that captures both aspects of what makes a good predictor is the Brier score (also explained in the addendum at the end of this post). The most illustrative examples are:
- A perfect predictor (100% confidence on things that happen, 0% confidence on things that don’t) would get a Brier score of 0.
- A perfect anti-predictor (0% confidence on things that happen, 100% confidence on things that don’t) would get a score of 1.
- A predictor that always predicts 50% would get a score of 0.25 (assuming the events they predict happen half the time). Thus, a score higher than 0.25 means someone’s accuracy is no better than if they simply guessed 50% for everything.
The mean Brier score across all our predictions is 0.217, and the median is 0.160. (Remember, lower is better.) 75% of focus area Brier scores are under 0.25 (i.e. they’re better than chance).[10]
This rather modest[11] Brier score together with overall good calibration implies our forecasts have low resolution.[12] Luke’s intuition on why there’s a significant difference in performance between these two dimensions of accuracy is that good calibration can probably be achieved through sheer reflection and training, just by being aware of the limits of one’s own knowledge, whereas resolution requires gathering and evaluating information about the topic at hand and carefully using it to produce a quantified forecast, something our grant investigators aren’t typically doing in much detail (most of our forecasts are produced in seconds or minutes). If this explanation is right, getting better Brier scores would require spending significantly more time on each forecast. We’re uncertain whether this would be worth the effort, since calibration alone can be fairly useful for decision-making and is probably much less costly to achieve, and our grant investigators have many other responsibilities besides making predictions.
2.5 Longer time horizons don’t hurt accuracy
Almost half of all our predictions are made less than 2 years before they will resolve (e.g. the prediction might be “X will happen within two years”),[13] with ~75% being less than 3 years out. Very few predictions are about events decades into the future.
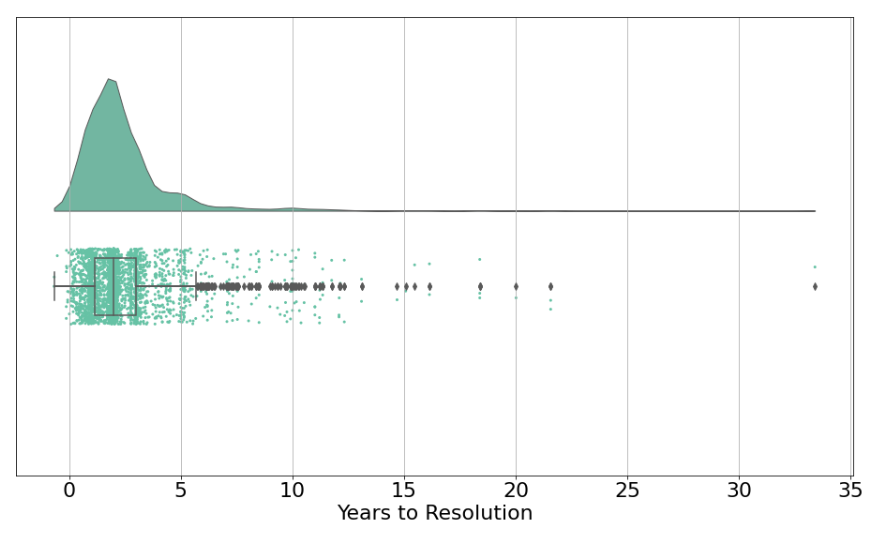
It’s reasonable to assume that (all else equal) the longer the time horizon, the harder it is to make accurate predictions.[14] However, our longer-horizon forecasts are about as accurate as our shorter-horizon forecasts.
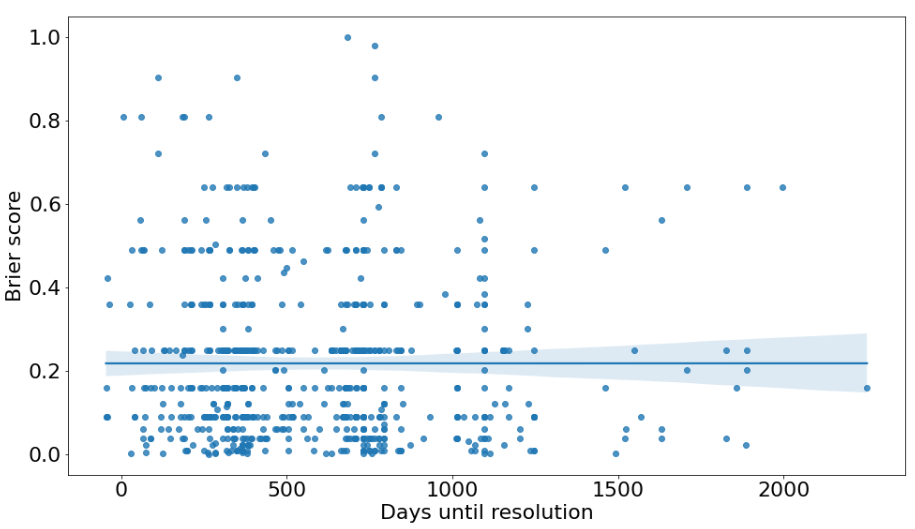
A possible explanation is question selection. Grant investigators may be less willing to produce long-range forecasts about things that are particularly hard to predict because the inherent uncertainty looks insurmountable. This may not be the case for short-range forecasts, since for these most of the information is already available.[15] In other words, we might be choosing which specific things to forecast based on how difficult we think they are to forecast regardless of their time horizon, which could explain why our accuracy doesn’t vary much by time horizon.
3. Caveats and sources of bias
There are several reasons why our data and analyses could be biased. While we don’t think these issues undermine our forecasting efforts entirely, we believe it’s important for us to explain them in order to clarify how strong the evidence is for any of our claims. The main issues we could identify are:
- Predictions are typically written and then later scored by the same person, because the grant investigator who made each prediction is typically also our primary point of contact with the relevant grantee, from whom we typically learn which predictions came true vs. false. This may introduce several biases. For example, predictors may choose events that are inherently easier to predict. Or, they may score ambiguous predictions in a way that benefits their accuracy score. Both things could happen subconsciously.
- There may be selection effects on which predictions have been scored. For example, many predictions have overdue scores, i.e. they are ready to be evaluated but have not been scored yet. The main reason for this is that some predictions are associated with active grants, i.e. grants that may be renewed in the future. When this happens, our current process is to leave them unscored until the grant investigator writes up the renewal, during which they are prompted to score past predictions. It shouldn’t be assumed that these unscored predictions are a random sample of all predictions, so excluding them from our analyses may introduce some hard-to-understand biases.
- The analyses presented here are completely exploratory. All hypotheses were put forward after looking at the data, so this whole exercise should be better thought of as “narrative speculations” rather than “scientific hypothesis testing.”
Addendum: Defining the Brier score
For binary events, the Brier score can be defined as
\( BS\,=\,\frac{1}{n} \sum_{i=1}^n (P_i\,-\,Y_i)^2 \)
Where \( i = 1,…,N \) ranges over events, \( p_i \) is the forecasted probability that the i-th event resolves True, and \( Y_i \) is the actual outcome of the i-th event (1 if True, 0 if False). A predictor that knows the base rate, b, of future events and predicts that on every event gets a Brier score of b * (1 – b). For example, if b = 50% (as is roughly the case for us), the expected Brier is 0.25. A perfect predictor (100% confidence on things that happen, 0% confidence on things that don’t) would get a Brief score of 0. A predictor that is perfectly anticorrelated with reality (predicts the exact opposite as a perfect predictor) would get a score of 1.
The Brier score can be decomposed into a sum of 3 components as
\( BS\,=\,E(p\, -\,P[Y|p])^2\,-\,E(P[Y|p]\,-\,b)^2\,+\,b\,*\,(1\,-\,b) \)
Where \( i = 1 \) denotes expectation, \( p_i \) is the forecasted probability of the event \(Y\), \(P[Y|p]\) is the actual probability of \(Y\) given that the forecasted probability was \(p\), and \(b\) is the base rate of \(Y\). The components can be interpreted as follows:
- The first one measures miscalibration. It is the mean squared error between forecasted and actual probabilities. It ranges from 0 (perfect calibration) to 1 (worst).
- The second one measures resolution. It is the expected improvement of one’s forecasts over the blind strategy that always outputs the base rate. It ranges from 0 (worst) to b(1-b) (best).
- The third one measures the inherent uncertainty of the events being forecasted. It is just the entropy of a binary event that happens with probability b.
In practice, because it is unlikely that any two events have the same forecasted probability, \(P[Y | p]\) is calculated by binning forecasts and averaging within each bin, i.e. the empirical estimate is \(P[Y | p]\) = (# of true predictions in that bin) / (total # of predictions in that bin). This is exactly what we do in our dashboards.
The post How accurate are our predictions? appeared first on Good Ventures.